

Web scraping is a method of extracting data from websites in an automatic manner. It’s an incredibly powerful tool for anyone who needs to get their hands on large amounts of data without having to manually enter it themselves. An increasing number of businesses are using web scraping as a way to collect information quickly and efficiently, but the process can be quite complex and intimidating for beginners. Luckily, there are a number of tools available to make web scraping much easier–and one of the most popular is Python. In this article, we’ll provide an overview of web scraping with Python and a few helpful tips to get started. https://gologin.com/blog/web-scraping-with-python
What is Web Scraping?
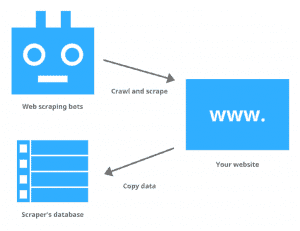
Web scraping, also referred to as web harvesting or web data extraction, is the process of extracting data from websites by parsing HTML code. It’s different than simply downloading a file because it requires more complicated logic; scraping programs must interact with webpages just like humans do, so they can extract useful data in a format that’s useful to humans.
Why use Python for Web Scraping?
Python is an excellent choice for web scraping because it is relatively simple to learn and widely used across the tech industry. Its syntax is straightforward and easy to read, which makes it ideal for working with HTML markup. Additionally, Python is very powerful and can handle complex web scraping tasks with ease — in some cases, you might even be able to do it with a single line of code! Finally, Python libraries such as BeautifulSoup and Requests make it extremely simple to parse and extract data from HTML pages.
With Python, web scraping is relatively straightforward. The first step is to install the appropriate libraries and frameworks, such as BeautifulSoup and Requests. Once these are installed, you can start writing your web scraping code. You will need to write functions that can send requests to webpages and parse HTML responses, extract relevant data, store it in a structured format, and then output it to a file. This process can be quite time-consuming and complex, but luckily there are a number of tutorials and other resources available to make it easier.
Best Practices for Web Scraping with Python
When it comes to web scraping with Python, there are a few best practices you should keep in mind. First, always make sure to respect the terms of service of the website you are scraping. Failing to do so may result in legal action. Additionally, be mindful of the rate at which you are sending requests — if you bombard a website with too many requests in a short period of time, you could risk getting blocked. It’s also important to ensure that your scraping code is written in a way that doesn’t break the website you are scraping, as this could potentially lead to data loss or instability. Additionally, be sure to monitor your web scraping code regularly to make sure it’s working properly and that any unexpected changes on the website you’re scraping have not caused any issues.

Finally, it’s important to note that Python is not the only language you can use for web scraping. If you are looking for more specialized tools, there are plenty of other languages to choose from, such as PHP, Ruby, and JavaScript. Additionally, there are many services and tools available that can help make web scraping easier, so don’t be afraid to take advantage of them.
Conclusion
Web scraping is a great way to quickly and easily gather large amounts of data from websites. Python is an excellent language for web scraping because it is simple and easy to use, and there are a number of helpful libraries and frameworks available to facilitate the process. By following best practices and taking advantage of available resources and tools, you can ensure that your web scraping efforts are successful.